
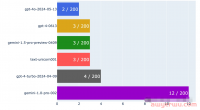
本月,openai发布了最新的gpt-4o,并给出了文本评测的结果。

通过这些统计数据,可以帮助我们选择最优的模型
选择最优模型
多任务语言理解上,建议选择 gpt-4o
研究生水平、复杂任务上,最好哪个都别选,自己去搜索、阅读。原因是:即使最优秀的gpt-4o,正确率才有53.6%,正确率太低了。回答一个问题,一半的概率是错误的。这谁敢放心啊。
在数学问题上,建议选择 gpt-4o。但是做好三成答案错误的心理准备。
编写代码问题上, 建议选择 gpt-4o
多语言小学数学问题,建议首选claude 3. 其次是:gpt-4o
阅读理解及推理:选择gpt-4T
测试的模型
openai测试了自己和其它3家公司的产品。
也就是说,openai认为, 只有这3家产品,能称得上是ChatGPT的竞争对手。
gpt-4系列: openai公司的产品
claude3: 据说是ChatGPT的最强竞争对手,由openai离职人员创办,谷歌有投资
Gemini: 互联网搜索巨头谷歌出品的AI
Llama3 400b: 是Meta(Facebook的母公司)出品的AI产品
测试项目
1.MMLU (%):
Measuring Massive Multitask Language Understanding
测试模型在大规模多任务语言理解上的表现。
2.GPQA (%):
Graduate-Level Google-Proof Q&A Benchmark
测试模型在研究生水平、难以通过简单搜索解答的问题上的表现。
3.MATH (%):
Measuring Mathematical Problem Solving with the MATH Dataset
测试模型在数学问题解决上的表现。
4.HumanEval (%):
Evaluating Large Language Models Trained on Code
测试模型在代码生成和编程任务上的表现。
5.MGSM (%):
Multilingual Grade School Math Benchmark
测试模型在多语言小学数学问题上的表现。
6.DROP (f1):
Discrete Reasoning Over Paragraphs
测试模型在阅读理解和需要离散推理的段落信息提取任务上的表现。
- ChatGPT:关于 Open AI 的 GPT-4 工具你需要知道的一切
- 如何创建Open AI API Key
- Open AI 的GPT商店终于来啦,下周发布!附详细创建教程
- Open AI Sora 超强文生视频如何使用:最新详细教程-小白教程
- Etsy 卖家如何利用好 Open AI Sora
- Open AI发布AI视频模型Sora,60秒视频碾压竞品,世界模型到来?
- ChatGPT注册详细教程来了(最新指南)
- ChatGPT注册方法,超详细的!但是小白不要尝试
- ChatGPT Plus会员升级实操指南:解锁全新ChatGPT-4.0体验
- New Bing:微软首款ChatGPT搜索,详细的申请教程来了!
- ChatGPT注册指南【保姆级手把手教程】
- 最新版ChatGPT下载安装教程(windows,Mac,Linux,Android)
- 一文看懂ChatGPT 4和3.5究竟有什么区别?ChatGPT账号值得充plus吗?
- ChatGPT注册教程(最新完整指南)
- ChatGPT 玩不了?新必应(New Bing)保姆级注册和申请教程来了!
- Claude官网地址多少?Claude怎么用?Claude和ChatGPT有和不同?
- 喜欢(0)
- 不喜欢(0)






 海华船务
海华船务 石南跨境工具导航
石南跨境工具导航 飞狮航空
飞狮航空 夏威夷航空货运追踪
夏威夷航空货运追踪 多洛米蒂航空货运追踪
多洛米蒂航空货运追踪 巴拿马航空货运追踪
巴拿马航空货运追踪 菲律宾航空货运追踪
菲律宾航空货运追踪 波兰航空货运追踪
波兰航空货运追踪 阿拉伯航空货运追踪
阿拉伯航空货运追踪 美国西南航空货运追踪
美国西南航空货运追踪

